Simple implementation of a customized torch.nn.module
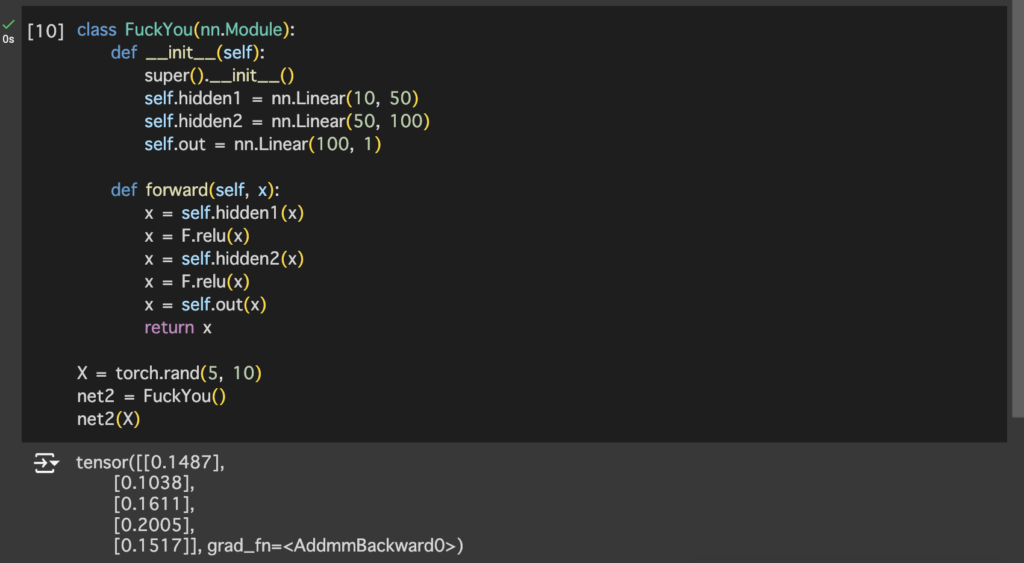
FuckYou need to be initialized first before use. When its initialized, it initializes its parent class (nn.Module) and build 3 layers per our defenition in __init__ function
You tell what you want this module to do in forward() method, you can do whatever the fuck you want to do in forward() function, like, if you want it to simply say “No”, you can do it. But in 99.999999% of the cases you want it to do the neural network thing, if so, you pass it layer by layer and activate after each layer as in that example
Or if you are more capable than me you can put them together or something I don’t know
__init__ defines what it is
forward defines what it does
Parameter management
Access
- All parameters are stored in module’s
- For a n layer net, <net.state_dict()> has the parameters of those n layers
- (0.weight, …), (0.bias, …), (2.weight, …), (2.bias, …), …
- For each layer, <net[i].state_dict()> has the parameter for that layer
- (weight, …), (bias, …), …
- For a n layer net, <net.state_dict()> has the parameters of those n layers
- All pairs in can be accessed by using <… for name, param in net.named_parameters()>
- If it’s the whole net, will include what layer that parameter is in (eg: (0.weight, …))
- To actually access the data inside:
- <net.state_dict[name].data>
- <layer.name.data>
- Without calling , it only returns the tensor as a whole object
- In nested modules:
- How to nest modules: (this is generated by calling print(rgnet))
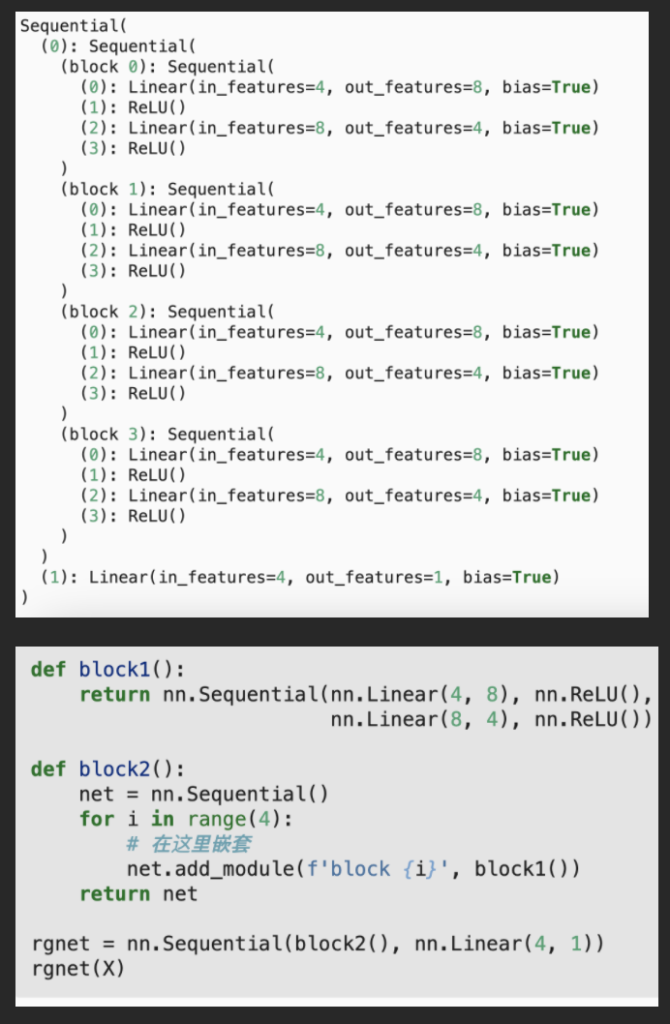
- How to access:
- <rgnet[0][2][0].bias.data> returns the bias value of the 1st hidden layer of block 2 in the 1st major part of rgnet
Initialization
- Basically, to directly access parameter data and change them
- built-in methods:
- <nn.init.method_name(layer.param_name, *args)>
- Typically a good idea to check layer validity, and after that method, the net need to apply that method. Below example shows these 2 processes:
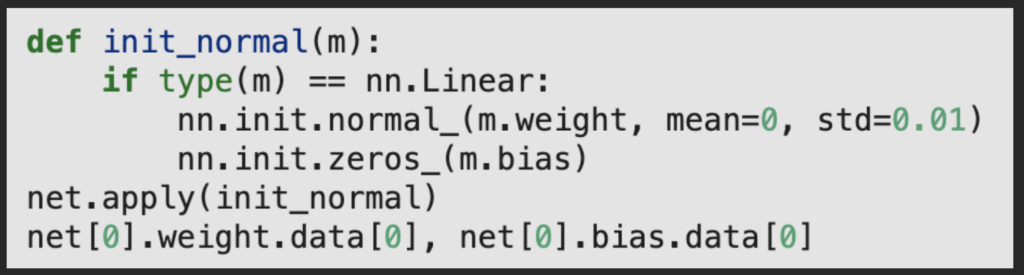
- If additional logic is needed, directly access those parameters and change them as needed
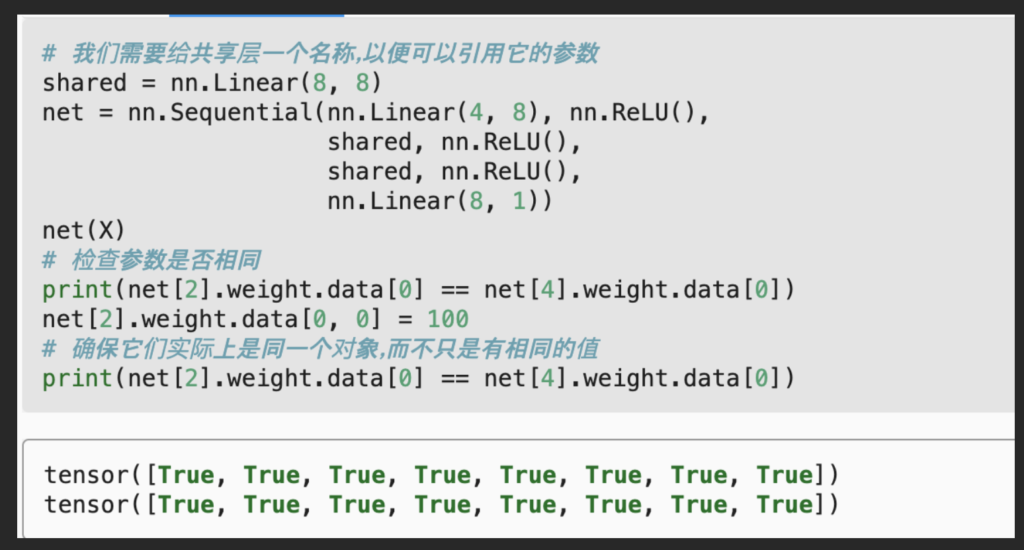
Sharing parameters
- Looks like we defined different layers at different positions, but we are actually using the same module at different positions
Customized layer
- The examples above are using nn.Linear, it automatically contains weight and bias
- nn.Sequential is a way to link those layers
- Sometimes we need something that is outside this default setting, are we need to define our own layers
- This can be done by:
- Inherit nn.Module
- Define whatever we need in init
- Define what we want it to do in forward(X, self), where self contains the thing we defined last step
- Use nn.sequential to link them
File save/load
- For tensor, dict:
- save: <torch.save(x, filename)>
- load: <a, b = torch.load(filename)>
- For model param:
- Suppose for a <class MLP()>:
- net = MLP()
- save: <torch.save(net.state_dict(), filename>
- load: <clone = MLP()>, <clone.load_state_dict(filename)>
- After we initialized a model of the original thing, we directly call this method to get its params
- load:
- After we initialized a model of the original thing, we directly call this method to get its params
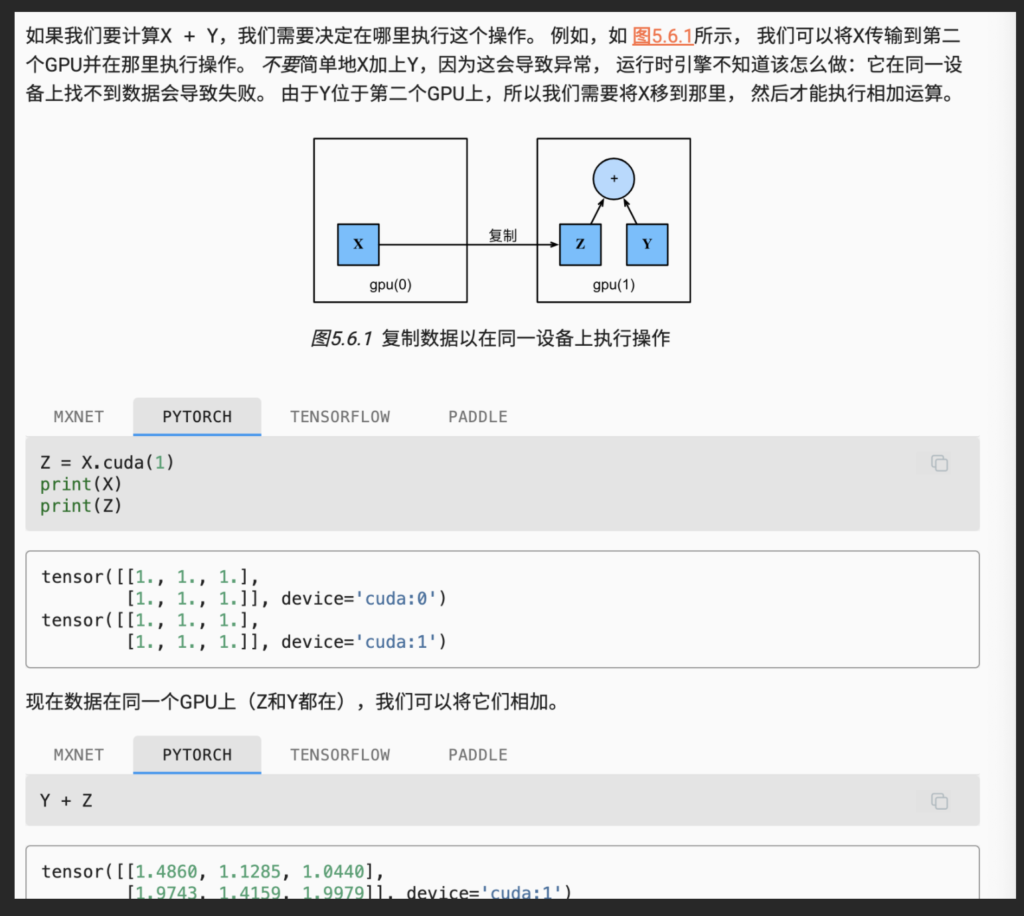
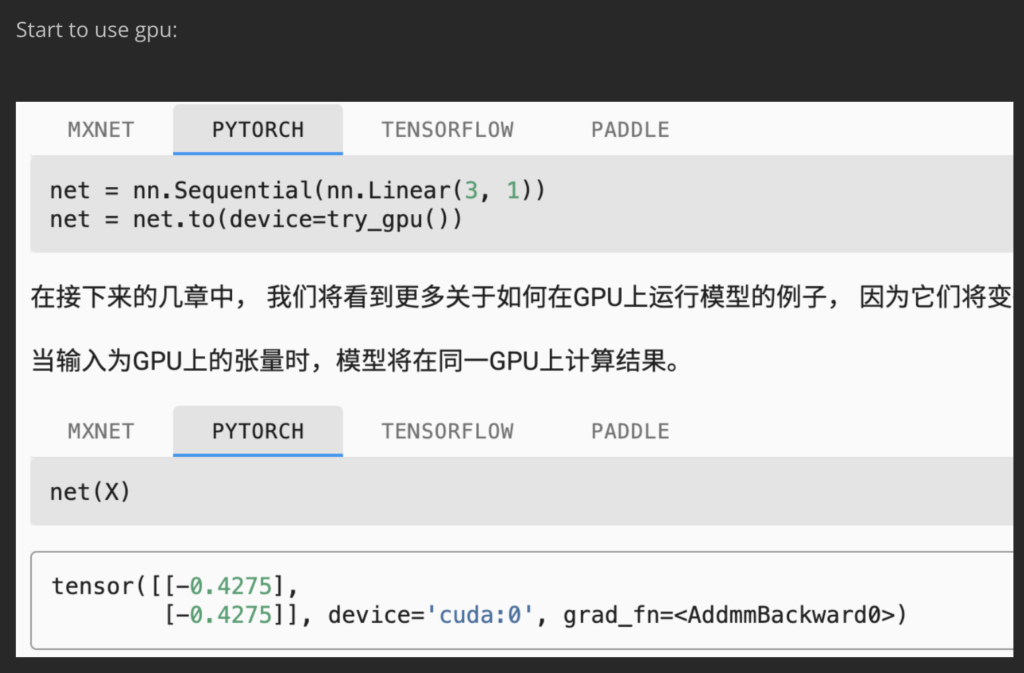
GPU
Comments are closed